本文最后更新于 2026年7月19日 晚上

作者:Mintimate
博客:https://www.mintimate.cn
Mintimate’s Blog,只为与你分享
前言
一般使用JDK,就是用OracleJDK或OpenJDK,OracleJDK商用许可证的协议经常变卦;稳妥起见,还是用OpenJDK进行项目开发比较好。
而OpenJDK的众多分支里,我比较喜欢ZuluJDK:https://www.azul.com/downloads/
但是有点尴尬,ZuluJDK的项目官网,不是很友好。有时候,即使上去了,速度也很慢,甚至一个JDK都下载不下来。
所以,我就想用我腾讯云轻量应用服务器的香港地区服务器进行中转,搭建自己的镜像站;搭建的镜像站,可以给我轻量应用服务器的上海、南京等地区提供下载直链;甚至还可以给小伙伴们下载JDK,分享喜悦( ´▽`)
ZuluJDK
ZuluJDK是基于OpenJDK开发出来的,使用的协议的:GPL v2 + Classpath exception (GPL v2 + CE):
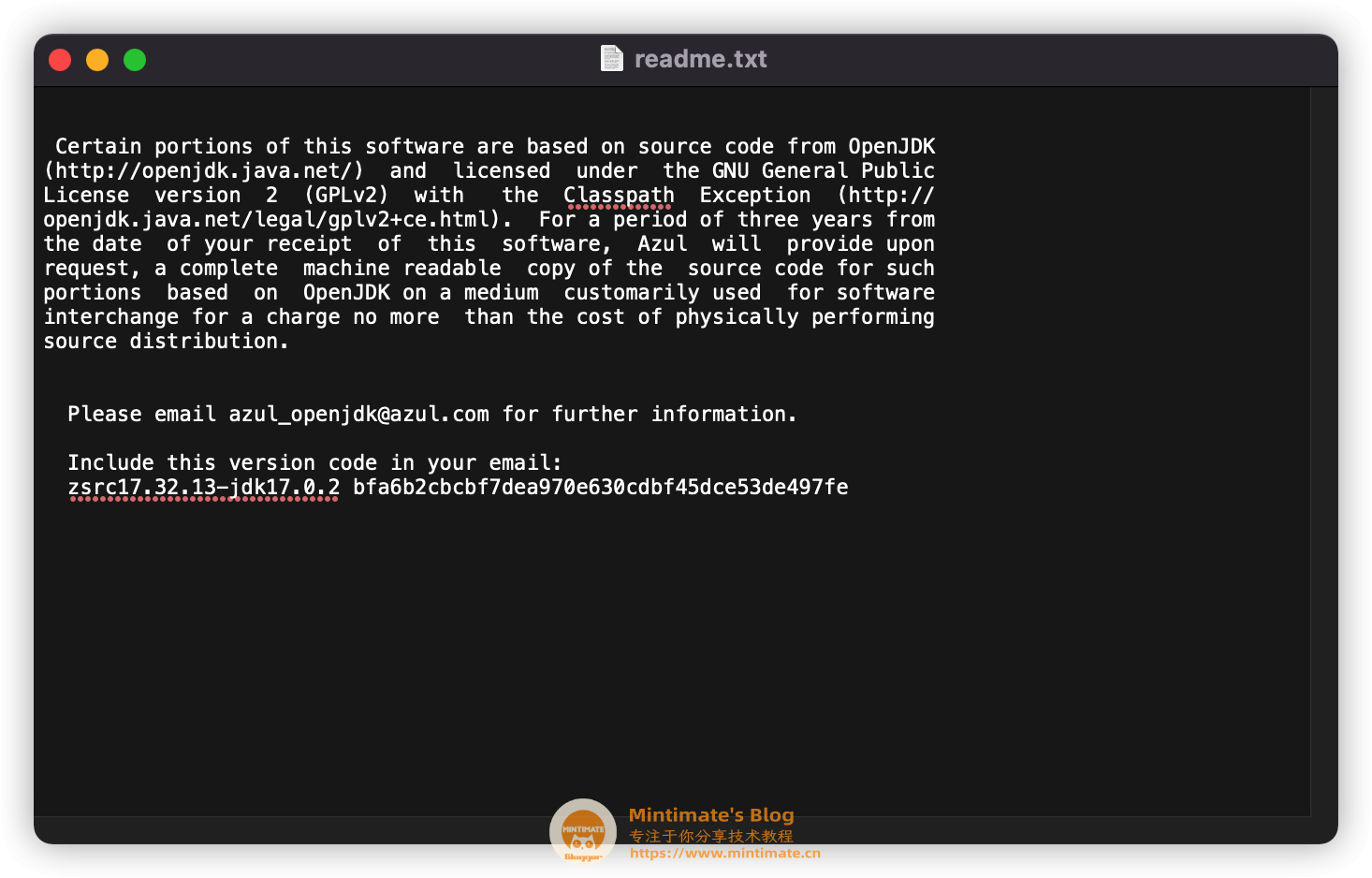
使用ZuluJDK,功能上基本和用OracleJDK没什么区别了,也不会受到Oracle的协议影响(ZuluJDK一直是GPL v2+CE)
关于使用OpenJDK开发Java软件,是否需要遵守 GPLv2而开源,这个还挺有热度讨论的;但是注意这个Classpath exception,我认为开发出的软件还是可以不使用GPL协议;具体怎么样,请求呼叫大佬在评论区支援(・_・;
设计思路
为了实现ZuluJDK最新版本的下载。准备使用Python解析ZuluJDk的下载地址,之后用wget下载到服务器上,最后使用Nginx进行目录映射。
环境依赖
环境依赖很简单,硬件方面:
- 腾讯云轻量应用服务器Debian镜像系统:Python使用其wget模块,调用系统wget;Windows操作系统不知道是否可以被Python调用wget。
紧急、限时推荐【强烈推荐】:
软件层面:
- Python3.x:核心软件,用于写爬虫。
- Vim8.2 With YCM:文本编辑器,用于写Python脚本。
- PAW:网络API测试软件,可用curll配合grep命令代替。
Python的模块依赖:
1
2
| requests==2.27.1
wget==3.2
|
数据获取
首先观察页面:https://www.azul.com/downloads/
发现数据接口:
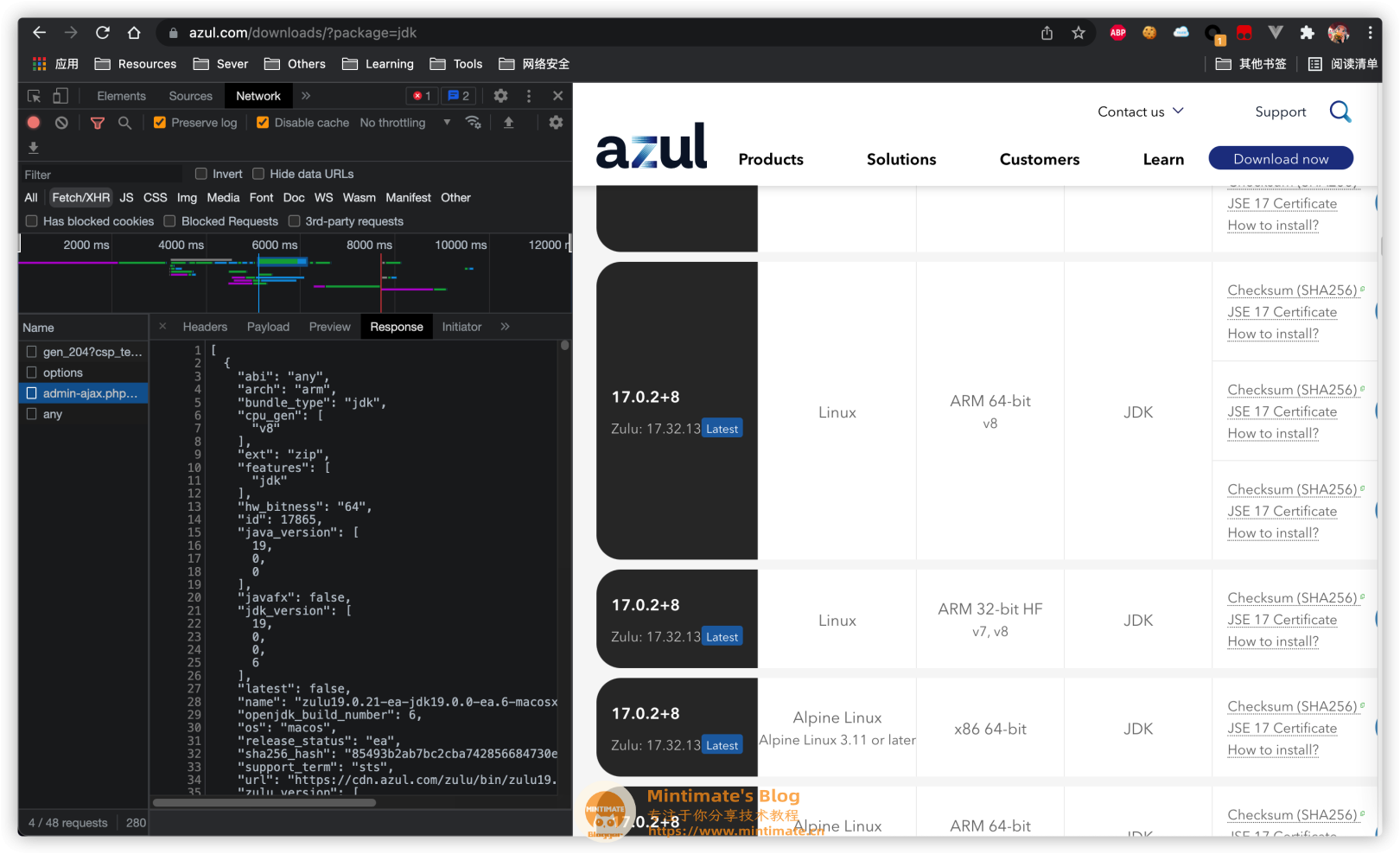
将其接口复制,使用paw或者postman进行测试:
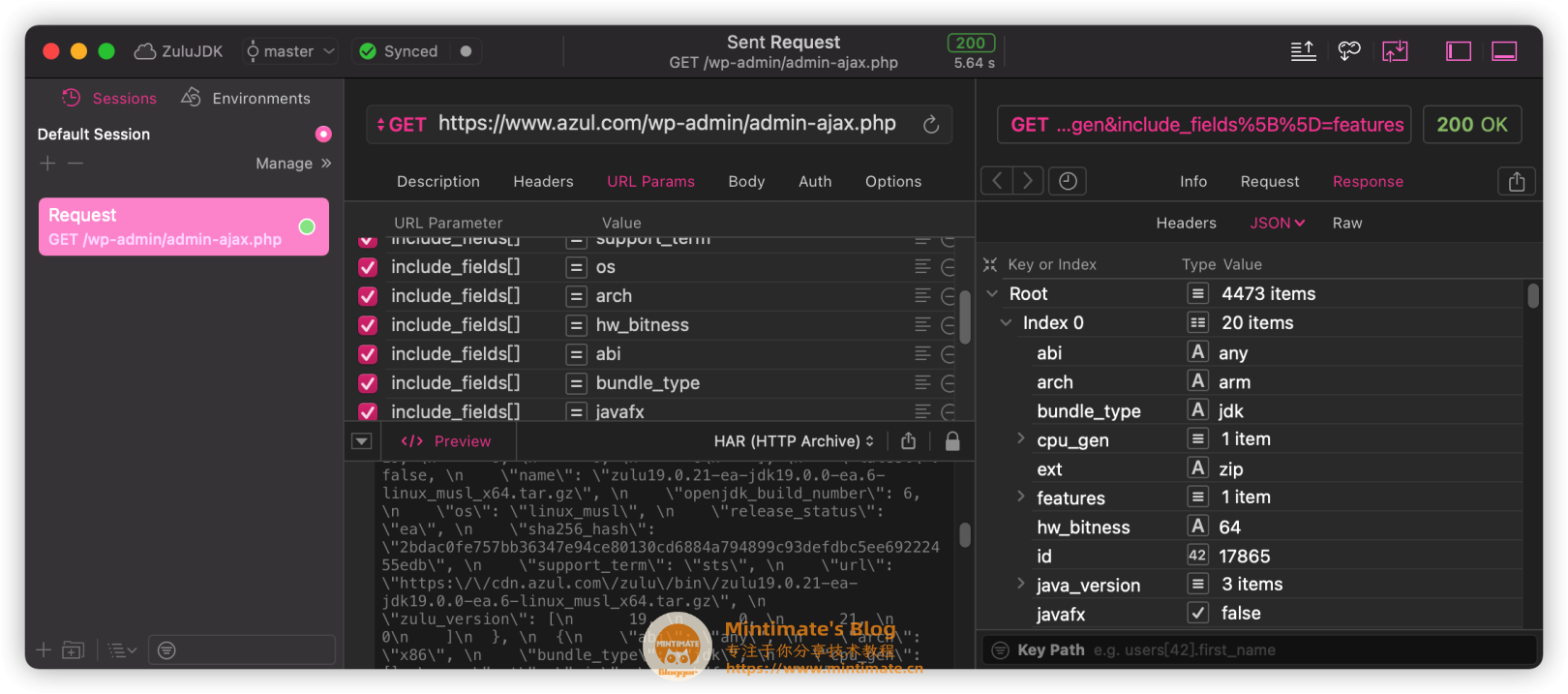
发现这个就是纯JSON对象,而且接收的请求:结构分明。
那设计就太简单了。
在Python里用requests库进行模拟请求,请求头:
1
2
3
4
5
6
7
8
9
| URL = "https://www.azul.com/wp-admin/admin-ajax.php?action=bundles&endpoint=community&use_stage=false&include_fields%5B%5D=java_version&include_fields%5B%5D=os&include_fields%5B%5D=javafx&include_fields%5B%5D=latest&include_fields%5B%5D=ext"
HEADERS = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'x-csrf-token': '',
'x-requested-with': 'XMLHttpRequest',
'cookie': ''
,
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36'
}
|
发送请求并解析为JSON:
1
2
3
4
| def get_zulu_json():
response = requests.get(url=URL,
headers=HEADERS).json()
return response
|
这样就可以把所有ZuluJDK的版本信息获取到了:
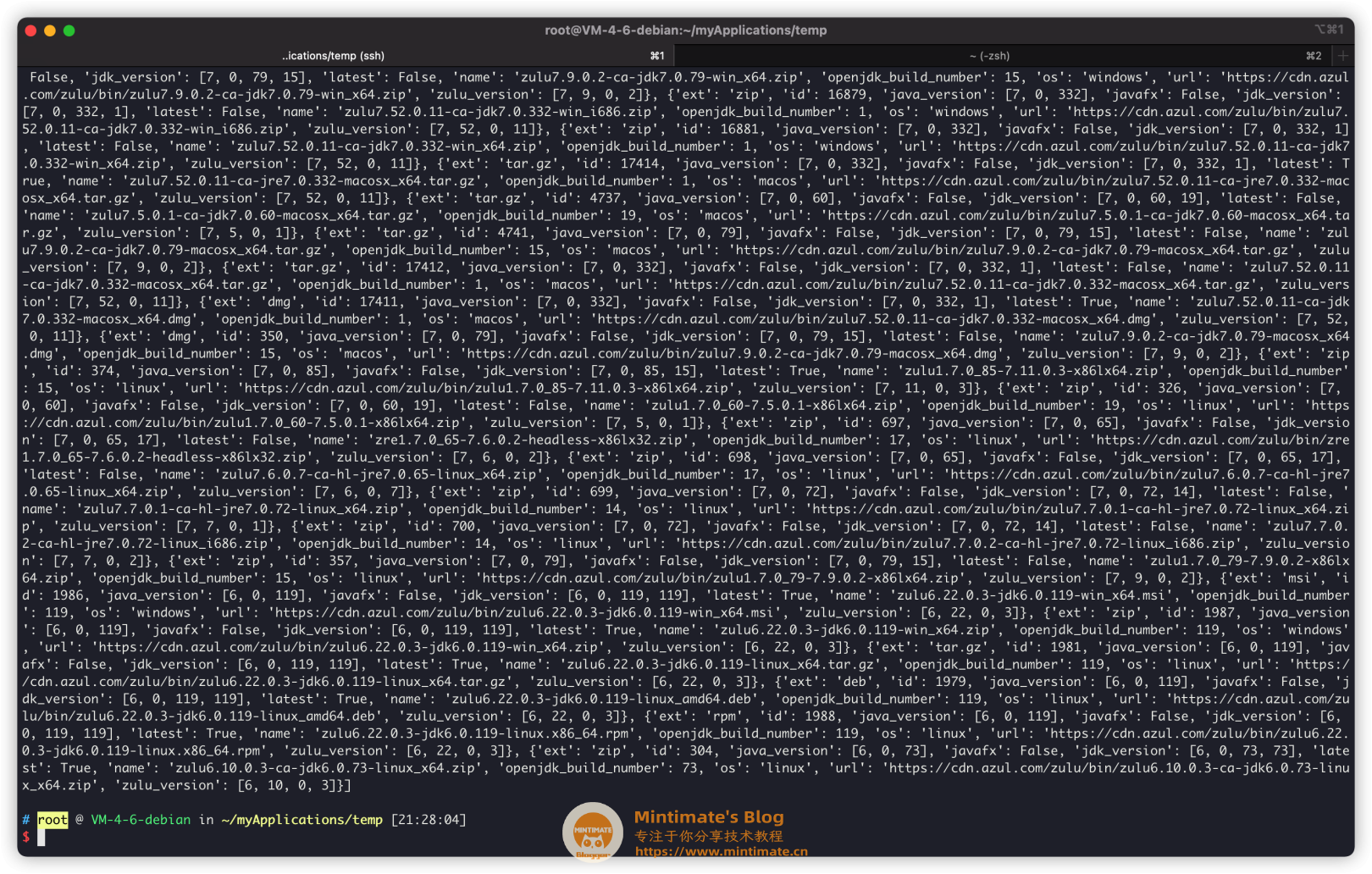
但是这样有点尴尬,没想到有这么多,直接把我腾讯云轻量应用服务器的控制台铺满了……
可怜的小白云,没事!!!我拿PAW去帮你分担压力~~~
PAW里显示,有4473项,显然是过去所有的构建版本都在这里了。
Zulu的服务器好大……4473个JDK/JRE……起码有1T的存储空间了。
所以我们需要过滤,简称:拆对象⁄(⁄ ⁄ ⁄ω⁄ ⁄ ⁄)⁄
数据处理
处理起来很简单,观察JSON对象的属性,举例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
| {
"abi": "any",
"arch": "arm",
"bundle_type": "jdk",
"cpu_gen": [
"v8"
],
"ext": "zip",
"features": [
"jdk"
],
"hw_bitness": "64",
"id": 17865,
"java_version": [
19,
0,
0
],
"javafx": false,
"jdk_version": [
19,
0,
0,
6
],
"latest": false,
"name": "zulu19.0.21-ea-jdk19.0.0-ea.6-macosx_aarch64.zip",
"openjdk_build_number": 6,
"os": "macos",
"release_status": "ea",
"sha256_hash": "85493b2ab7bc2cba742856684730ee42a8ee71d3d0a510770a5d0071a2622903",
"support_term": "sts",
"url": "https://cdn.azul.com/zulu/bin/zulu19.0.21-ea-jdk19.0.0-ea.6-macosx_aarch64.zip",
"zulu_version": [
19,
0,
21,
0
]
},
|
可以看到,有ext、latest和name等等参数。一般JDK都是自己配置,操作系统一般也就是Windows、Linux和macOS。
不会有人是用安装器安装的吧?不会吧,不会吧,不好吧……用安装器安装,到时候卸载会不会找不到它(。 ́︿ ̀。)
macOS和Linux的ZuluJDK,通用的肯定是归档文件(tar、tar.gz),Windows的ZuluJDk都是zip文件,且os="windows"。
所以我们过滤两次。(拆两次对象,芜湖,我好坏)
macOS/Linux
所以我们对JSON进行过滤:
1
2
3
4
5
6
7
8
9
10
11
| def filter_by(zulu_info, latest=None, javafx=None, ext=None, os=None):
params = locals()
params.pop('zulu_info')
for key in params:
if params[key] is None:
continue
if zulu_info.get(key) != params[key]:
return False
return True
download_list=list(filter(lambda x: filter_by(x, javafx=True, ext="tar.gz"), zulu_json))
|
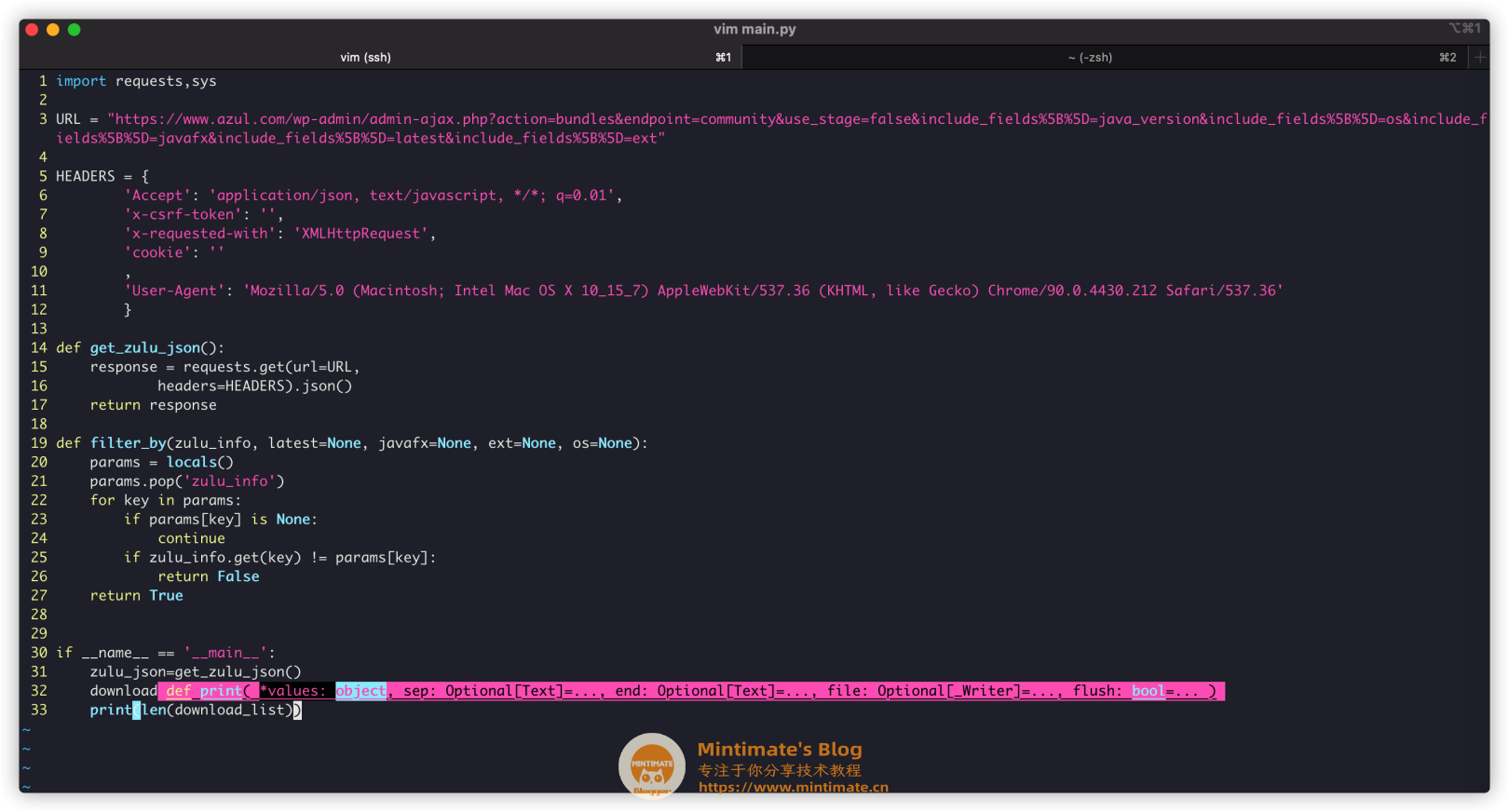
其中:
zulu_json:上文数据爬取得到的JSON(就是那个4000多对象的◡ ヽ(`Д´)ノ ┻━┻)
计算长度看看:

真不错,只有342项了。
但是这里还有JRE,小伙伴还需要JRE???
直接砍了!!!并且你可以发现,这个JSON对象,数据越前,版本越新。我们就每次只缓冲下载最新版本的吧:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
temp_list = {}
for item in filtered_list:
if re.search(r"jdk", item['name']) is None:
continue
jdk_version_code = str(item['jdk_version'][0])
OS_version = jdk_version_code + item['name'].split("-")[-1]
if OS_version in temp_list.keys():
continue
else:
temp_list[OS_version] = 1,
|
这样,就可以保证,每个系统的每个大版本,只下载一次:
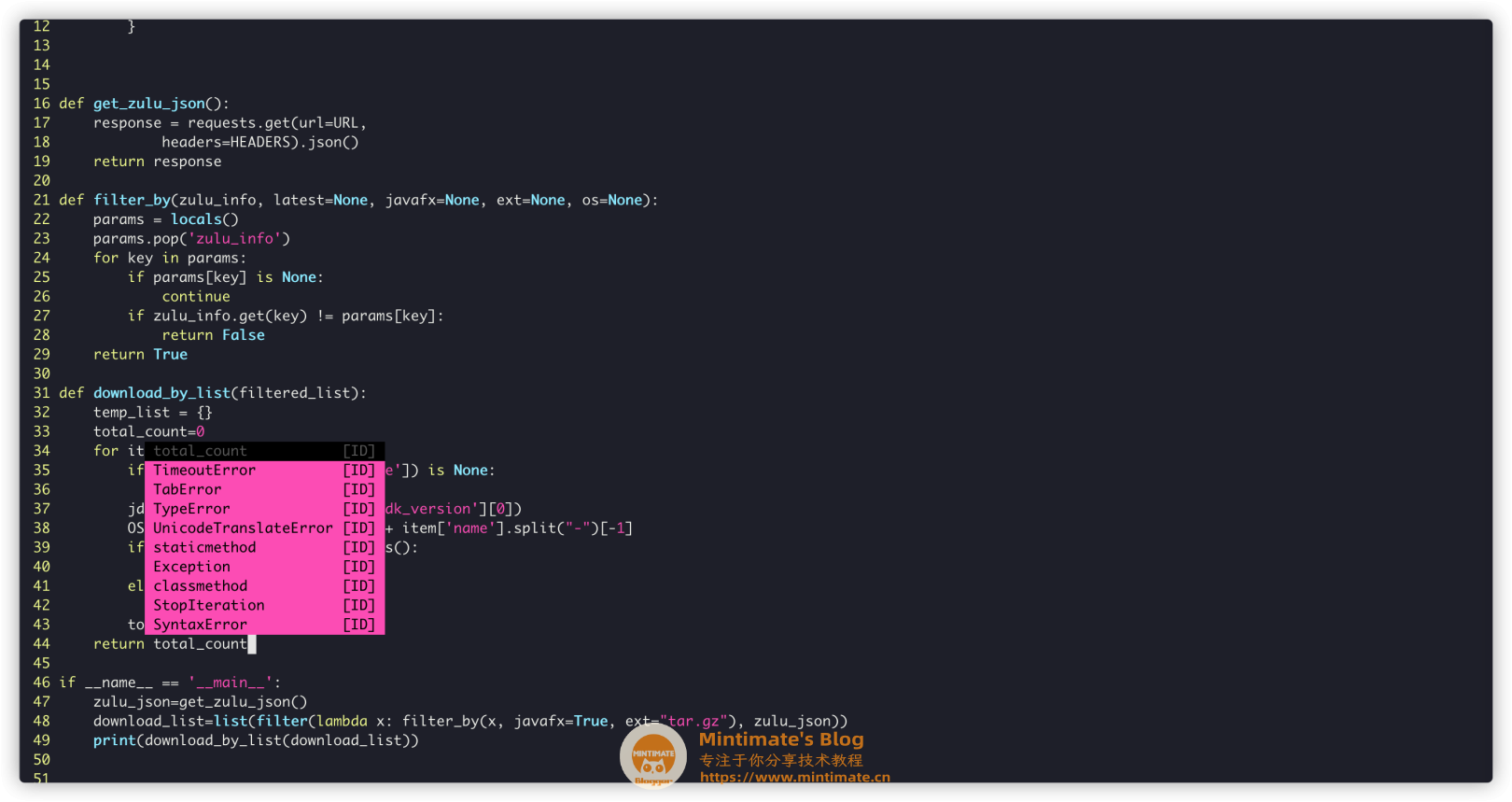

可以看到,这样的话342项就变成只有27项了(macOS/Windows)
Windows
Windows的过滤和下载macOS和Linux的方法一样了:
1
| download_list=list(filter(lambda x: filter_by(x, javafx=True, ext="zip",os="windows"), zulu_json))
|
和刚刚Linux方法一样,再过滤掉JRE,只留最新版本:
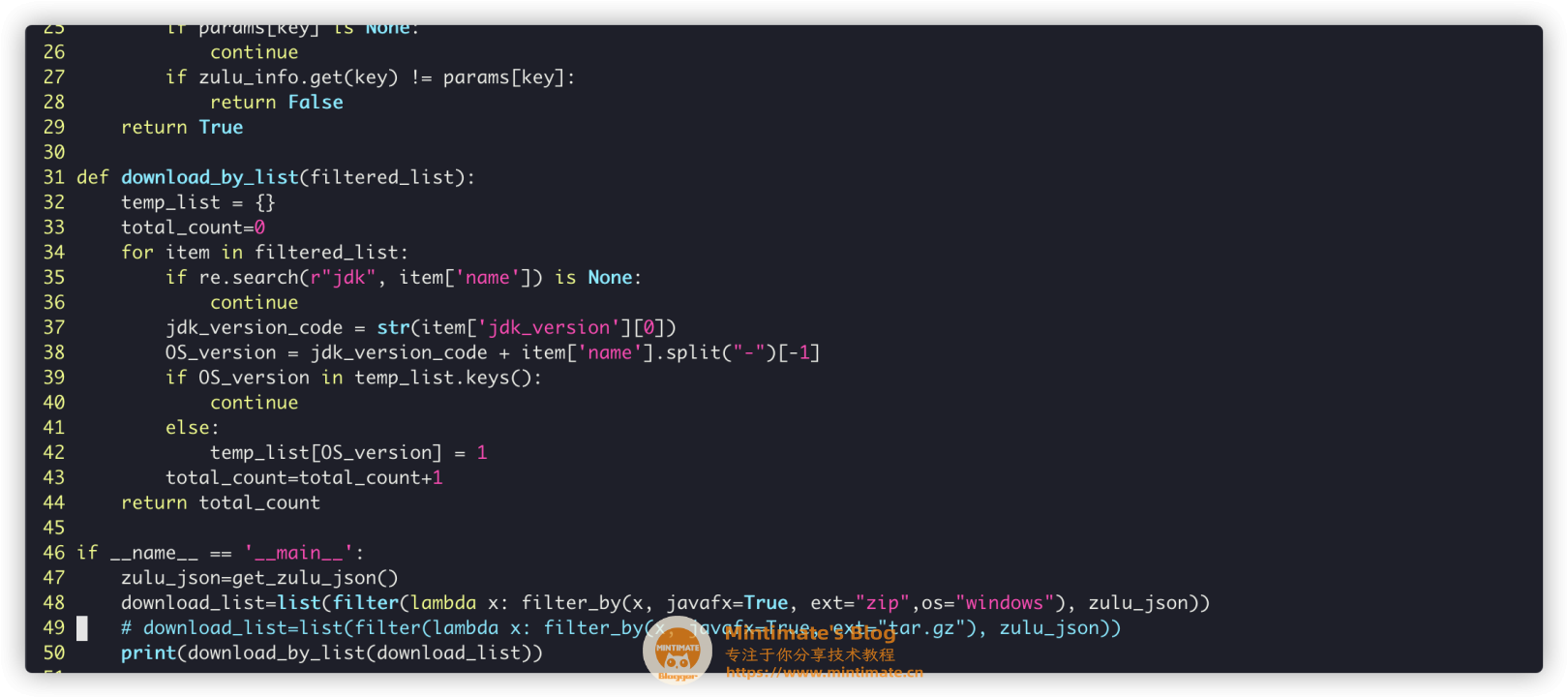

这样看来,下载的内容不多(27+12)
下载JDK
最后,我们就是下载了。这里使用wget对数据进行下载;Python的wget模块:https://pypi.org/project/wget/
这个可不是GNU的wget工具,是用来Python里调用wget进行下载的。
安装wget模块:

定义一个下载目录:
1
2
3
| def has_dir(path):
if not os.path.exists(path):
os.makedirs(path)
|
之后不全过滤时候的代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
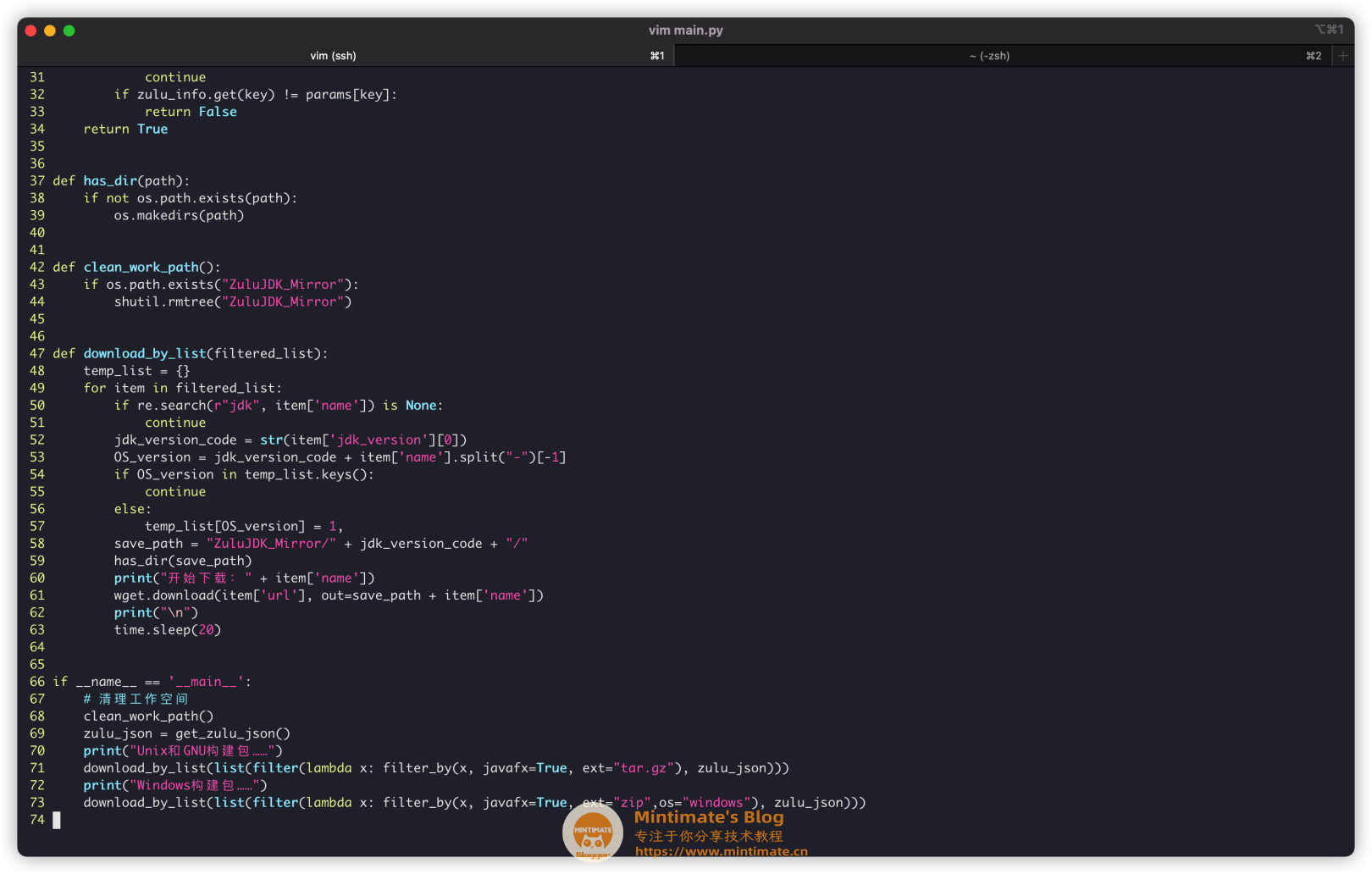
| def download_by_list(filtered_list):
temp_list = {}
for item in filtered_list:
if re.search(r"jdk", item['name']) is None:
continue
jdk_version_code = str(item['jdk_version'][0])
OS_version = jdk_version_code + item['name'].split("-")[-1]
if OS_version in temp_list.keys():
continue
else:
temp_list[OS_version] = 1,
save_path = "ZuluJDK_Mirror/" + jdk_version_code + "/"
has_dir(save_path)
print("开始下载:" + item['name'])
wget.download(item['url'], out=save_path + item['name'])
print("\n")
time.sleep(20)
|
最后效果
最后,我们编写的Python脚本:
使用Python命令运行:
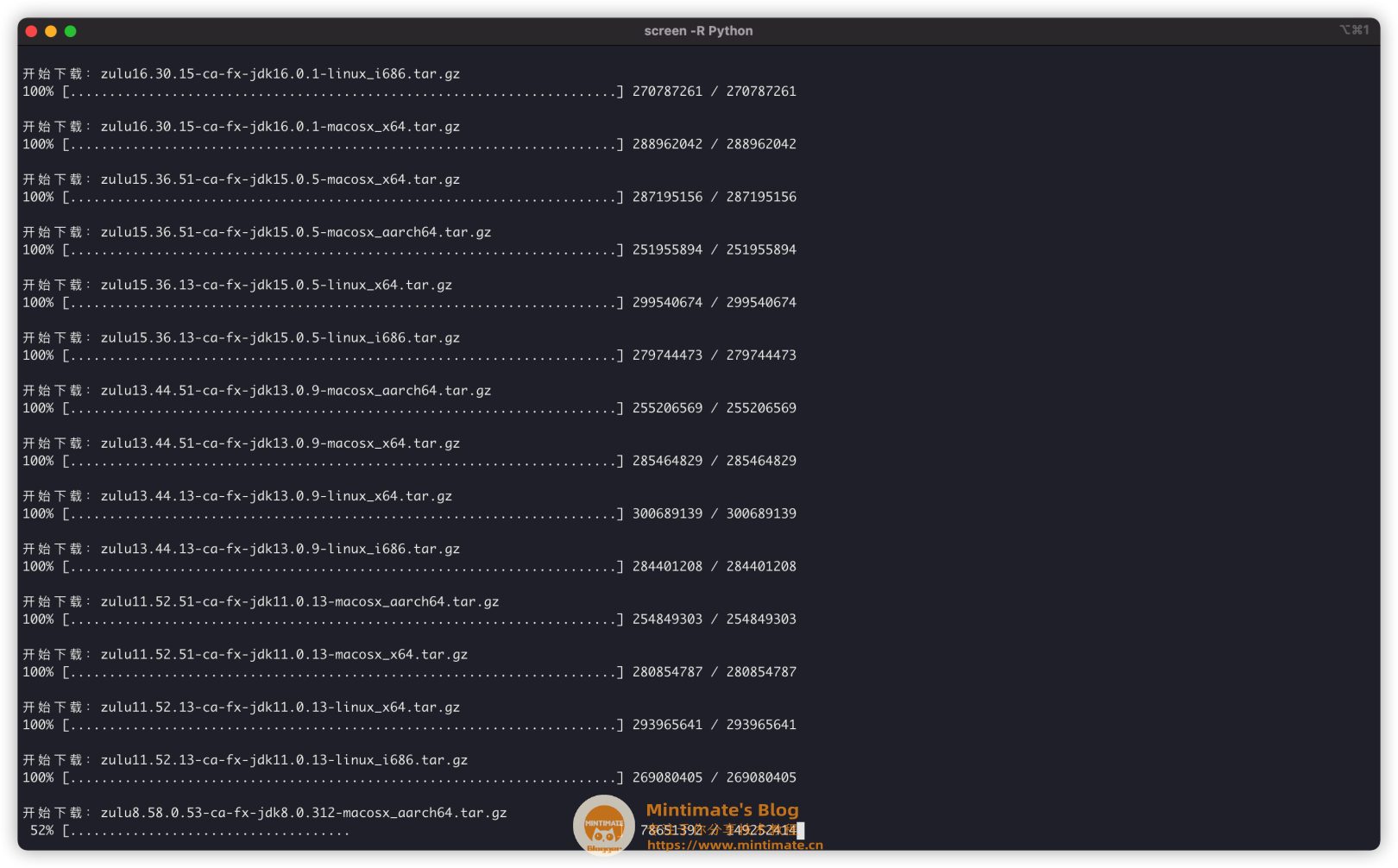
最后下载下来的文件:
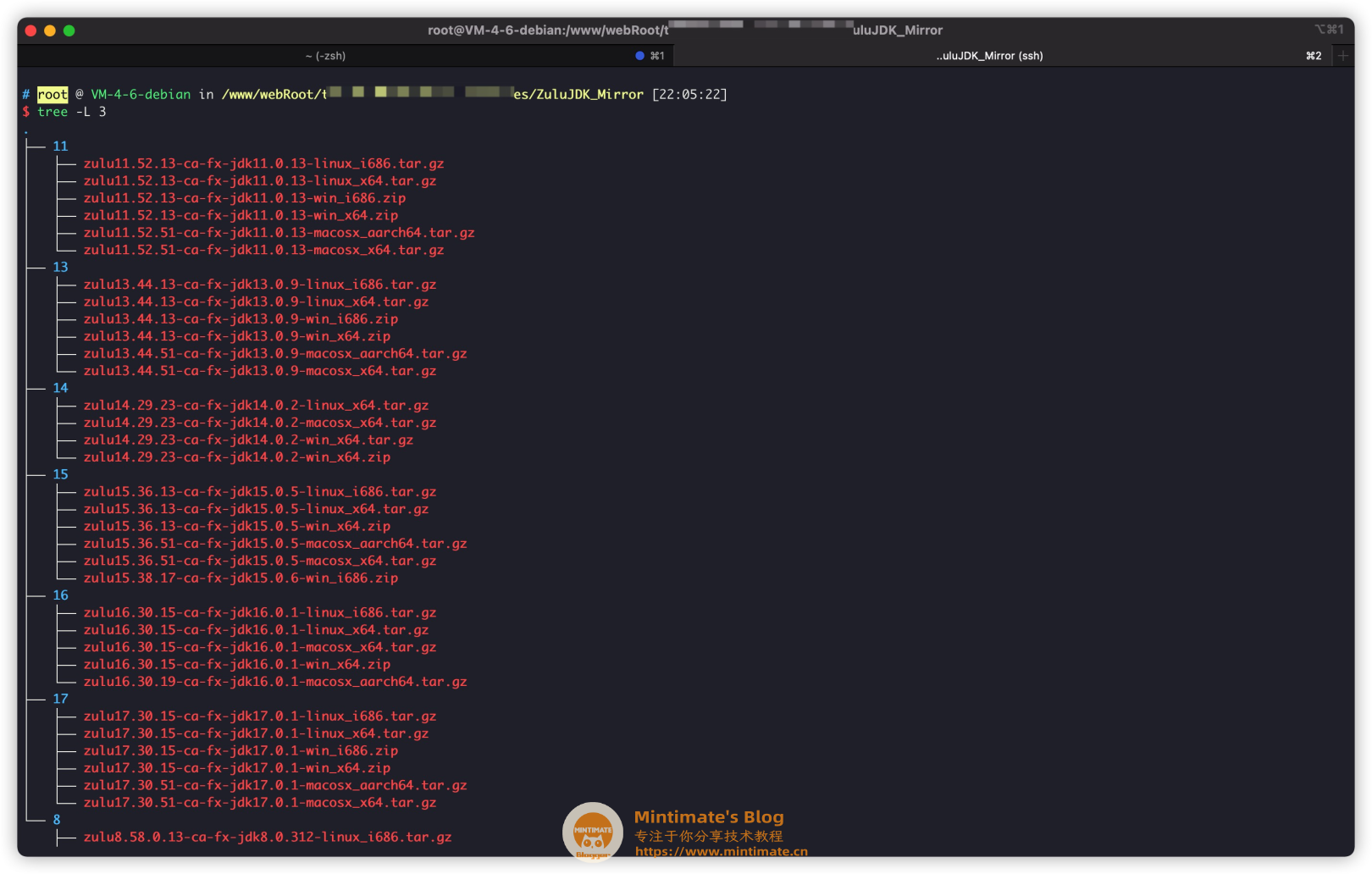
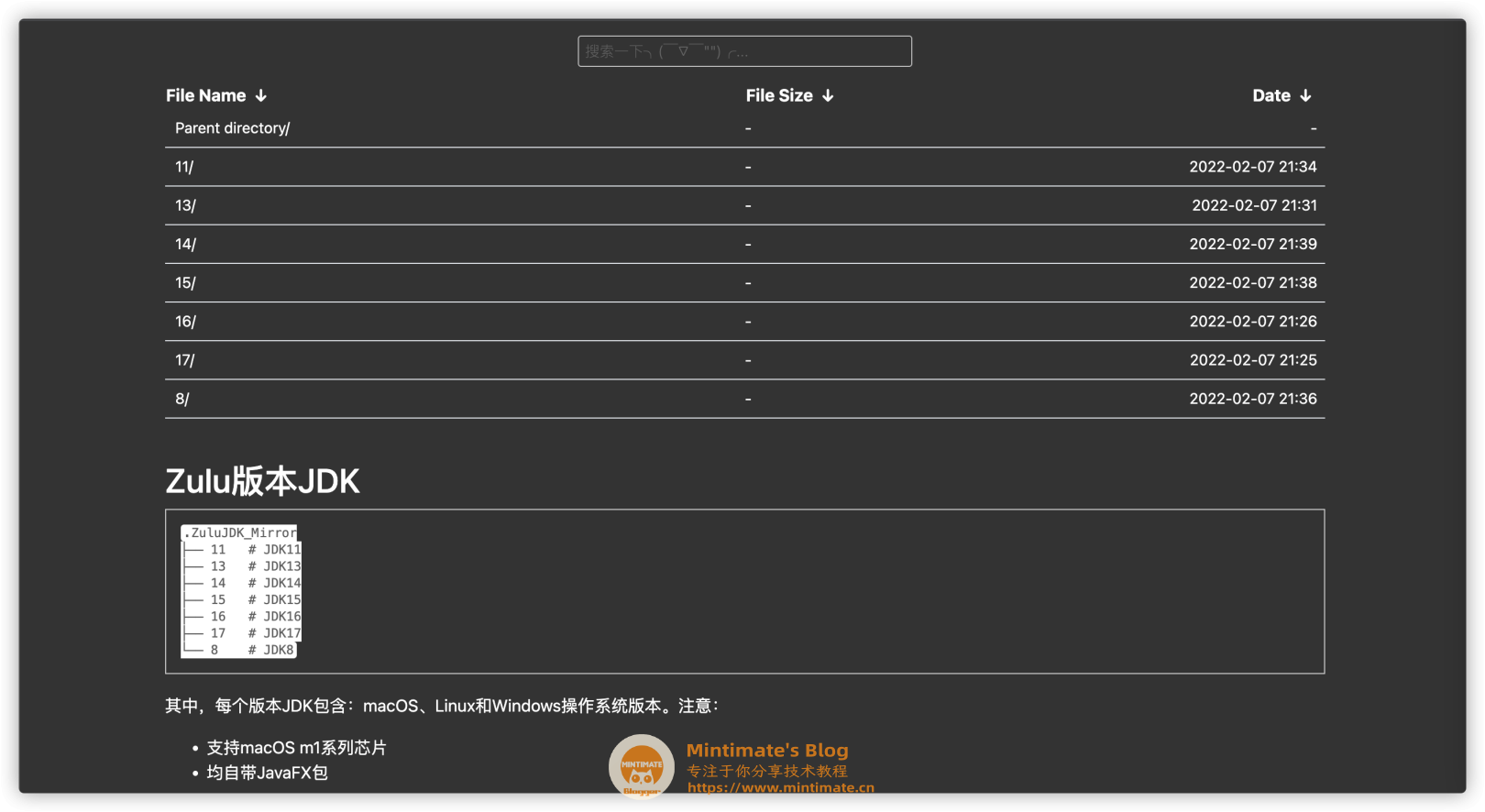
使用Nginx做个目录映射:
当然,我们可以使用Cron定期缓冲最新版本的ZuluJDK,这里就不演示了。
END
最后,我们就可以把Nginx目录映射的地址发给想下载ZuluJDK的小伙伴了。
另外…… 突然发现:我直接解析了ZuluJDK的直链,用Nginx进行反代……似乎更方便;还不用占服务器空间!!!
不过,还是这样好点,确保资源持久化~~~而且,腾讯云轻量应用服务器的中国香港地区硬盘资源,更充分地使用了,享受自己造“轮子”的快乐(*☻-☻*)
